Github:本文代码放在该项目中:NLP相关Paper笔记和代码复现
说明:讲解时会对相关文章资料进行思想、结构、优缺点,内容进行提炼和记录,相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
这里我们来好好探讨一下深度学习中,专门用于序列数据处理的Tokenizer,它可以帮助我们快速的建立词汇表字典,并提供了各种方法,针对文本和序列之间的转换,极大的方便的使用。TensorFlow中有keras实现的Tokenizer,而PyTorch本身是没有Tokenizer,但是我们可以通过引入torchtext或torchnlp库达到同样的效果,本文将对这几种工具的分词器部分的使用进行说明讲解。使用到的计算框架版本如下:
- TensorFlow:2.3.1
- PyTorch:1.7.0
- torchtext:0.8.0
- torchnlp:0.5.0
这里我想多提一点,可能有助于后面内容的理解。我研究了这些分词器的源码,其实内部实现并不是很复杂,除了torchtext特殊一点(所以它也是使用起来最复杂的一个),torchtext不仅仅是分词器的作用,它还同时做了词嵌入,所以你使用它的时候可以选择用何种预训练词嵌入模型,如果词汇数量够多,你甚至可以直接使用内置的词向量嵌入数据,复杂但是功能齐全.
而torchnlp和Tokenizer则是通过维护一个内部词汇表,不过区别在于,torchnlp内部表有两个,分别是index_to_token和token_to_index,一个是list,一个是dict,词汇的分布则是按照token出现的顺序进行编码的。而Tokenizer同样也有两个,一个是word_index和index_word,都是dict,不过它们维护的词汇分布则是按照词汇的频率由高到低,相同频率则按照出现顺序进行编码的。
本文主要讲解使用方法,不讲解内部原理,有兴趣的可以去看看它们的源码实现,逻辑性还是很清晰的,看着很舒服。
TensorFlow中的Tokenizer
其实相对而言,使用Keras的Tokenizer比较顺畅,一种丝滑的感觉(封装的比较完整),使用它我们可以对文本进行预处理,序列化,向量化等。Tokenizer基于矢量化语料库、单词数、TF-IDF等,将每个文本转换为整数序列(每个整数是字典中标记的索引)或转换成矢量(其中每个标记的系数可以是二进制的)。
Tokenizer
1
2
3
4
5
6
7
8
9
10
11
12
| www.tensorflow.org
tf.keras.preprocessing.text.Tokenizer(
num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True,
split=' ', char_level=False, oov_token=None, document_count=0, **kwargs
)
参数:
num_words:根据单词频率,保留的最大单词数。仅保留最常见的num_words-1个单词,也就是保留前num_words-1个频率高的单词,不会影响内部词汇表的大小,但是会限制text和sequence转换的词汇量大小。
filters:一个字符串(注意,不是正则表达式字符串哦),其中每个元素都是将从文本中过滤掉的字符。默认值为所有标点符号,加上制表符和换行符,再减去'字符。
lower:bool类型,是否将文本转换为小写。
split:字符串,分隔词的分隔符,用于split()方法。
char_level:如果为True,则每个字符都将被视为token。
oov_token:如果给定的话,它将被添加到word_index中,并在text_to_sequence调用期间用于替换词汇外的单词,字典中的编码一直都是第一个。
|
默认情况下,Tokenizer将删除所有标点符号,从而将文本转换为以空格分隔的单词序列(单词可能包含'字符)。 然后将这些序列分为token列表,然后将它们编码索引或向量化。注意了,0是一个保留索引,不会分配给任何单词。下面通过调用代码以及输出效果直观的展示用法,也能体会深刻,具体方法的参数和含义,自行查看官方文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| text = [
"你 去 那儿 竟然 不喊 我 生气 了",
"道歉 ! ! 再有 时间 找 你 去"
]
tokenizer = tf.keras.preprocessing.text.Tokenizer(oov_token='<UNK>', num_words=None)
tokenizer.fit_on_texts(text)
print(tokenizer.word_counts)
print(tokenizer.word_index)
print(tokenizer.index_word)
print(tokenizer.num_words)
print(tokenizer.document_count)
print(tokenizer.index_docs)
print(tokenizer.word_docs)
print(tokenizer.texts_to_sequences(text))
print(tokenizer.texts_to_matrix(text, "binary"))
sequence = [[2, 3, 5, 6, 7, 8, 9, 10], [11, 4, 4, 12, 13, 14, 2, 3]]
print(tokenizer.sequences_to_matrix(sequence))
print(tokenizer.sequences_to_texts(sequence))
|
torchnlp
PyTorch-NLP是Python中的自然语言处理(NLP)库。 它是根据最新的研究成果而构建的,从一开始就旨在支持快速原型设计。 PyTorch-NLP带有预训练的嵌入,采样器,数据集加载器,度量,神经网络模块和文本编码器。编码方法里面很多,这里使用比较典型的StaticTokenizerEncoder进行说明。
Welcome to Pytorch-NLP’s documentation!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| pytorchnlp.readthedocs.io
torchnlp.encoders.text.StaticTokenizerEncoder(
sample, min_occurrences=1, append_sos=False, append_eos=False, tokenize=<function _tokenize>,
detokenize=<function _detokenize>, reserved_tokens=['<pad>', '<unk>', '</s>', '<s>', '<copy>'],
sos_index=3, eos_index=2, unknown_index=1, padding_index=0, **kwargs
)
参数:
sample: 用于构建编码字典的数据样本
min_occurrences (int, optional): 要添加到编码字典中的token的最小出现次数。
tokenize (callable): 序列的分词方法
detokenize (callable): 序列的token合并方法
append_sos (bool, optional): 如果为True,则在编码向量中插入SOS token。
append_eos (bool, optional): 如果为True,则在编码向量中插入EOS token。
reserved_tokens (list of str, optional): 将保留标记列表插入字典开头。
sos_index (int, optional): sos token用于编码序列的开头,即token所在的索引。
eos_index (int, optional): eos token用于编码序列的开头,即token所在的索引。
unknown_index (int, optional): unk token用于编码序列的开头,即token所在的索引。
padding_index (int, optional): pad token用于编码序列的开头,即token所在的索引。
batch (list of torch.Tensor): 编码序列的batch大小
lengths (torch.Tensor): 编码序列中,序列的长度列表
dim (int, optional): 指定分隔的序列维度
|
传给StaticTokenizerEncoder的sample是一个序列列表,这个和在Tokenizer中的是差不多的,tokenize和Tokenizer中的split是类似的功能,只不过tokenize传入的是方法,StaticTokenizerEncoder内部有一个初始化的token列表,长这样:
1
| ['<pad>', '<unk>', '</s>', '<s>', '<copy>']
|
然后添加进来的序列就在其末尾进行顺序的补入,还有要说的就是,如果上面关于sos、eos等等的参数没有特别指定,就直接使用这个初始化列表里面的token。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| texts = [
"你 去 那儿 竟然 不喊 我 生气 了",
"道歉 ! ! 再有 时间 找 你 去"
]
tokenizer = StaticTokenizerEncoder(sample=texts, tokenize=lambda x: x.split())
print(tokenizer.index_to_token)
print(tokenizer.token_to_index)
print(tokenizer.vocab)
print(tokenizer.vocab_size)
print([tokenizer.encode(text) for text in texts])
print(stack_and_pad_tensors([tokenizer.encode(text) for text in texts]))
print(stack_and_pad_tensors([tokenizer.encode(text) for text in texts])[0])
|
torchtext
torchtext库是PyTorch项目的一部分,和torchvision等一样,和torch核心库分离开,从torchtext这个名字我们也能大概猜到该库是pytorch圈中用来预处理文本数据集的库,torchtext在文本数据预处理方面特别强大。使用它来对文本数据进行预处理简直不要太方便,提供了非常多的API使用。当然本文主要是说明文本序列转换方面的,具体torchtext的完整使用,就不做赘述,想要深入了解的可以参考其官方文档。
TorchText
我这里简单的概括一下它在数据预处理方面的简单流程,让你有个简单的了解。
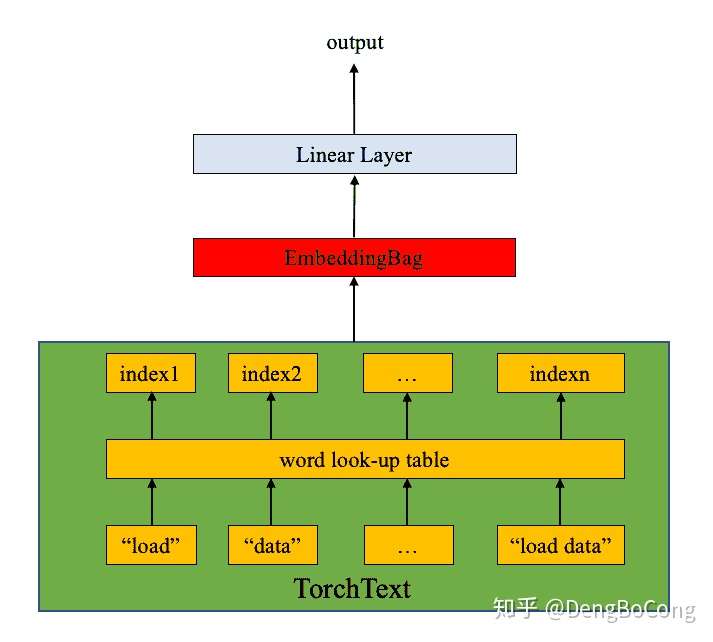
- Train/Validation/Test数据集分割
- 文件数据导入(File Loading)
- 分词(Tokenization) 文本字符串切分为词语列表
- 构建词典(Vocab) 根据训练的预料数据集构建词典
- 数字映射(Numericalize/Indexify) 根据词典,将数据从词语映射成数字,方便机器学习
- 导入预训练好的词向量(word vector)
- 分批(Batch) 数据集太大的话,不能一次性让机器读取,否则机器会内存崩溃。解决办法就是将大的数据集分成更小份的数据集,分批处理
- 向量映射(Embedding Lookup) 根据预处理好的词向量数据集,将5的结果中每个词语对应的索引值变成 词语向量
除了第一步和最后一步需要我们使用其他库或者自己编写方法外,其他所有的步骤,torchtext都提供了API。言归正传,说会文本数据转换。如果你使用上面的预处理流程,就可以得到关于贴合原数据的向量序列。这里我就不说这种方法,我这里说一下,使用现有字典或预训练模型进行转换的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| torchtext.data.functional.sentencepiece_numericalizer(sp_model)
sp_id_generator = sentencepiece_numericalizer(sp_model)
list_a = ["sentencepiece encode as pieces", "examples to try!"]
list(sp_id_generator(list_a))
torchtext.data.functional.numericalize_tokens_from_iterator(vocab, iterator, removed_tokens=None)
vocab = {'Sentencepiece' : 0, 'encode' : 1, 'as' : 2, 'pieces' : 3}
ids_iter = numericalize_tokens_from_iterator(vocab,
simple_space_split(["Sentencepiece as pieces",
"as pieces"]))
for ids in ids_iter:
print([num for num in ids])
|
Author:
DengBoCong
Permalink:
http://dengbocong.cn/Deep-Learning/14c91d9dedcf/
License:
Licensed under the Apache License, Version 2.0 (the "License")
Slogan:
Stay hungry, Stay foolish.