前言
说明:讲解时会对相关文章资料进行思想、结构、优缺点,内容进行提炼和记录,相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
Subword算法在预训练语言模型中有着不小的地位,它在分词和字典方面的优化改进带来的影响,间接或直接影响着任务最终的性能效果,因此,作为NLP研究者或开发者,有必要了解下Subword算法的原理。
介绍
在NLP领域,对语料进行预处理的过程中,我们需要进行分词和生成词典。很多时候用多了框架的API,觉得分词和生成字典就是调用的事情,不过事情并没有那么简单,比如其中涉及到的未登录词的问题,就对任务性能影响很大。一种很朴素的做法就是将未见过的词编码成#UNK ,有时为了不让字典太大,只会把出现频次大于某个阈值的词丢到字典里边,剩下所有的词都统一编码成#UNK 。
未登录词:简单来讲就是在验证集或测试集出现了训练集从来没见到过的单词。
总结而言就是,任务(如对话、机翻)的词表是定长的,但是需要实际输入的词汇是开放的(out of vocabulary)。以前的做法是新词汇添加到词典中,但是过大的词典会带来两个问题:
- 稀疏问题:某些词汇出现的频率很低,得不到充分的训练
- 计算量问题:词典过大,也就意味着embedding过程的计算量会变大
对于分词和生成字典方面,常见的方法有:
- 给低频次再设置一个back-off 表,当出现低频次的时候就去查表
- 不做word-level转而使用char-level,既然以词为对象进行建模会有未登录词的问题,那么以单个字母或单个汉字为对象建模不就可以解决了嘛?因为不管是什么词它肯定是由若干个字母组成的。
第一种方法,简单直接,若干back-off做的很好的话,对低频词的效果会有很大的提升,但是这种方法依赖于back-off表的质量,而且也没法处理非登录词问题。第二种方法,的确可以从源头解决未登录词的问题,但是这种模型粒度太细。
下面举例word-level和subword-level的一种直观感受:
1 | 训练集的词汇: old older oldest smart smarter smartest |
Subword算法
如何将词分解成subword,依据不同的策略,产生了几种主流的方法: Byte Pair Encoding (BPE)、wordpiece 和 Unigram Language Model等。值得一提的是,这几种算法的处理流程跟语言学没有太大的关系,单纯是统计学的解决思路,Subword模型的主要趋势:
- 与单词级别的模型架构相同,但使用的是字符级别的输入
- 采用混合架构,输入主要是字符,但是会混入其他信息
Byte Pair Encoding(BPE)
BPE算法流程可参考论文。Byte Pair Encoding最初是一种压缩算法,其主要是使用一些出现频率高的byte pair来组成新的byte。但它也可以作为一种分词算法(尽管其本质是自下而上的聚类方法),它以数据中所有(Unicode)字符的单字组词汇开头并且使用最常见的n-gram对来组成一个新的n-gram。例如”loved”,”loving”,”loves”这三个单词,其本身的语义都是”爱”的意思。BPE通过训练,能够把上面的3个单词拆分成”lov”,”ed”,”ing”,”es”几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量。
这个算法有一些需要注意的地方:
- 有一个目标词汇量大小并在到达时停止训练
- 需要确定单词的最长分割片段
- 分词过程仅在由某些先前的标记器(通常为MT的Moses标记器)标识的单词内进行。
- 自动决定系统的词汇,不再以常规方式过度使用“单词”
获取subword词表的流程(learn-bpe):
- 准备足够大的训练语料
- 确定期望的subword词表大小
- 将单词拆分为字符序列并在末尾添加后缀“ </ w>”,统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w </ w>”:5
- 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
- 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1
示例:
1 | 第一步:{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3} |
实现(论文给出示例,如下):
编码和解码(apply-bpe及其逆过程):
- 在之前的算法中,我们已经得到了subword的词表,对该词表按照子词长度由大到小排序。编码时,对于每个单词,遍历排好序的子词词表寻找是否有token是当前单词的子字符串,如果有,则该token是表示单词的tokens之一。
- 我们从最长的token迭代到最短的token,尝试将每个单词中的子字符串替换为token。 最终,我们将迭代所有tokens,并将所有子字符串替换为tokens。 如果仍然有子字符串没被替换但所有token都已迭代完毕,则将剩余的子词替换为特殊token,如
。
停止符”“的意义在于表示subword是词后缀。举例来说:”st”字词不加”“可以出现在词首如”st ar”,加了”“表明改字词位于词尾,如”wide st“,二者意义截然不同。
示例:
1 | 编码过程: |
更直观的以单词“where”为例,首先按照字符拆分开,然后查找词表文件,逐对合并,优先合并频率靠前的字符对。85 319 9 15 表示在该字符对在词表文件中的评率排名。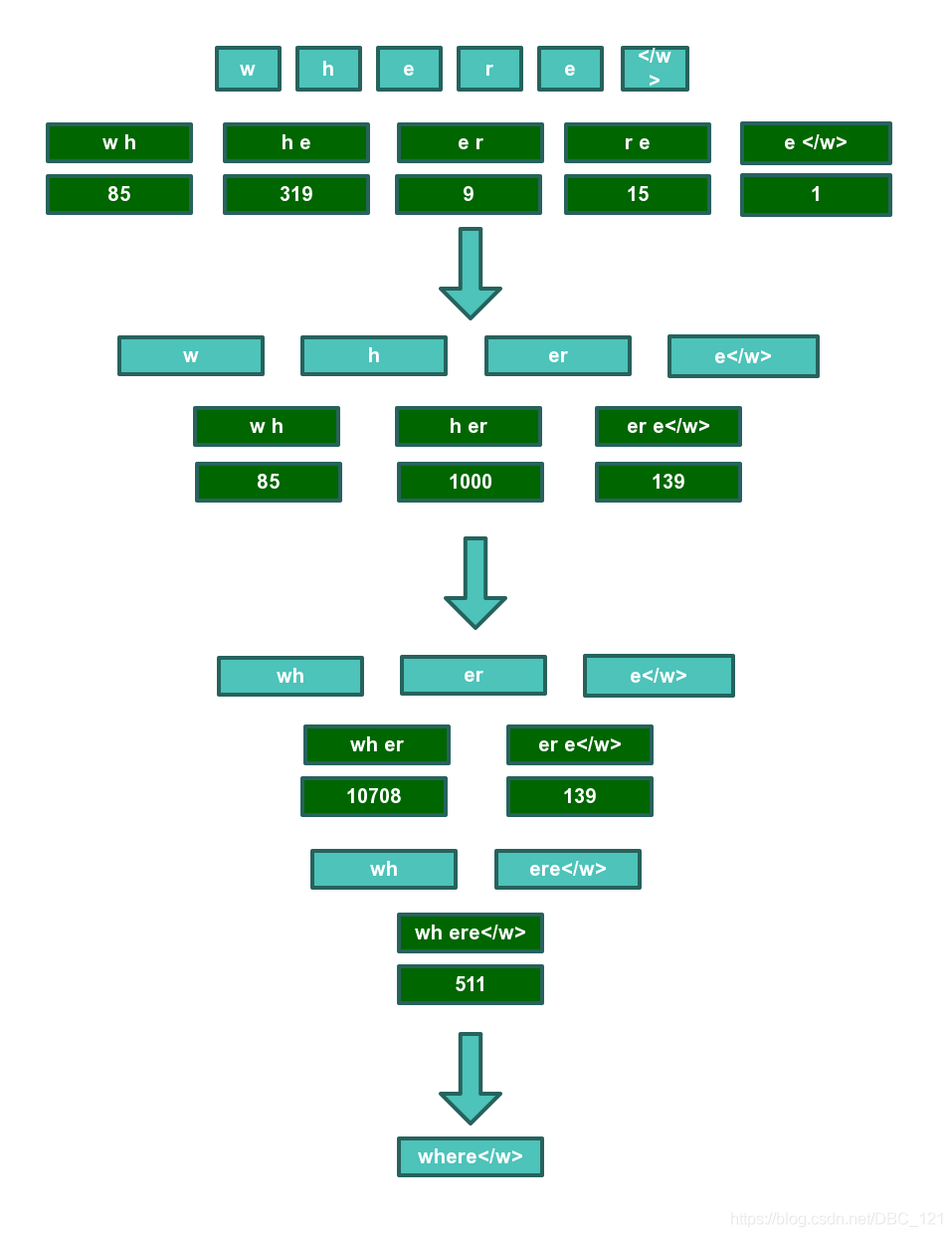
最终where可以在词表文件中被找到,因此where的bpe分词结果为where,对于其他并不能像where一样能在词表文件中找到整个词的词来说,bpe分词结果以最终查询结束时的分词结果为准。
Wordpiece\Sentecepiece model
Google NMT使用了借鉴了上面的方法,其V1使用的是wordpiece mode,V2使用的是sentecepiece model。它并没有采取字符集别的n-gram计数方法,而是使用贪心近似来最大化语言模型日志可能性来选择片段。添加n-gram信息,是为了最大限度地减少perplexity,Wordpiece模型标记化内部的单词,Sentencepiece模型则对原始文本进行处理。
wordpiece作为BERT使用的分词方式,其生成词表的方式和BPE非常相近,都是用合并token的方式来生成新的token,最大的区别在于选择合并哪两个token。BPE选择频率最高的相邻字符对进行合并,而wordpiece是基于概率生成的。
BERT模型使用的是wordpiece的变体,对于一些常见词如1910s、at、fairfax等词直接使用,对于其他词则根据wordpieces来构建。所以,需要注意方在其他任务中使用bert时,必须处理这个问题。
Choose the new word unit out of all possible ones that increase the likelihood on the training data the most when added to the mode.
从字面上可能有些难以理解,列一下公式就比较清楚了。在做分词的时候假设词和词之间是独立的,所以句子的likelihood等于句子中每个词概率的乘积:
$$logP(Sentence)=\sum_{i=1}^nlogP(t_i) \quad if\ Sentence\ has\ token\ t_1…t_n$$
如果把相邻的 $x$ 和 $y$ 两个token合并生成一个新的token叫做 $z$,那么整个句子likelihood的变化可以用下面的式子来表达:
$$logP(t_z)-(logP(t_x) + logP(t_y))=log\frac{P(t_z)}{P(t_x\cdot P(t_y))}$$
这不就是两个token之间的互信息嘛!所以wordpiece和BPE的核心区别就在于wordpiece是按token间的互信息来进行合并而BPE是按照token一同出现的频率来合并的。
wordpiece算法中subword词表的学习跟BPE也差不多:
- 准备语料,分解成最小单元,比如英文中26个字母加上各种符号,作为原始词表
- 利用上述语料训练语言模型
- 从所有可能的subword单元中选择加入语言模型后能最大程度地增加训练数据概率的单元作为新的单元
- 重复上步骤,直至词表大小达到设定值或概率增量低于某一阈值
unigram language model
语言模型作为NLP的大厦根基,也是unigram分词的基础。在wordpiece算法中,其实已经用到了language modeling,在选择token进行合并的时候目标就是能提高句子的likelihood。而unigram分词则更进一步,直接以最大化句子的likelihood为目标来直接构建整个词表。
首先,了解一下怎么样在给定词表的条件下最大化句子的likelihood。 给定词表及对应概率值: {“你”:0.18, “们”:0.16, “好”:0.18, “你们”:0.15},对句子”你们好“进行分词:
- 划分为”你” “们” “好” 的概率为 0.180.160.18=0.005184
- 划分为”你们” “好” 的概率为 0.15*0.18=0.027
明显看出后一种分词方式要比前一种好,当然在真实的案例下词表可能有几万个token,直接罗列各种组合的概率显然不可能,所以需要用到Viterbi算法。因此在给定词表的情况下,可以
- 计算每个token对应的概率
- 找到一个句子最好的分词方式
但是在词表没有确定的情况下,同时要优化词表和词表里每个token的概率很难做到。unigram分词使用逐步迭代的方式来求解,具体步骤如下:
- 首先初始化一个很大的词表
- 重复以下步骤直到词表数量减少到预先设定的阈值:
- 保持词表不变,用EM算法来求解每个token的概率
- 对于每一个token,计算如果把这个token从词表中移除而导致的likelihood减少值,作为这个token的loss
- 按loss从大到小排序,保留前n%(原文中为80%)的token。
初始化词表可以用不同的方法,一个比较直接的办法就是用所有长度为1的token加上高频出现的ngram来作为起始词表。
其他Subword模型
- Fully Character-Level Neural Machine Translation without Explicit Segmentation
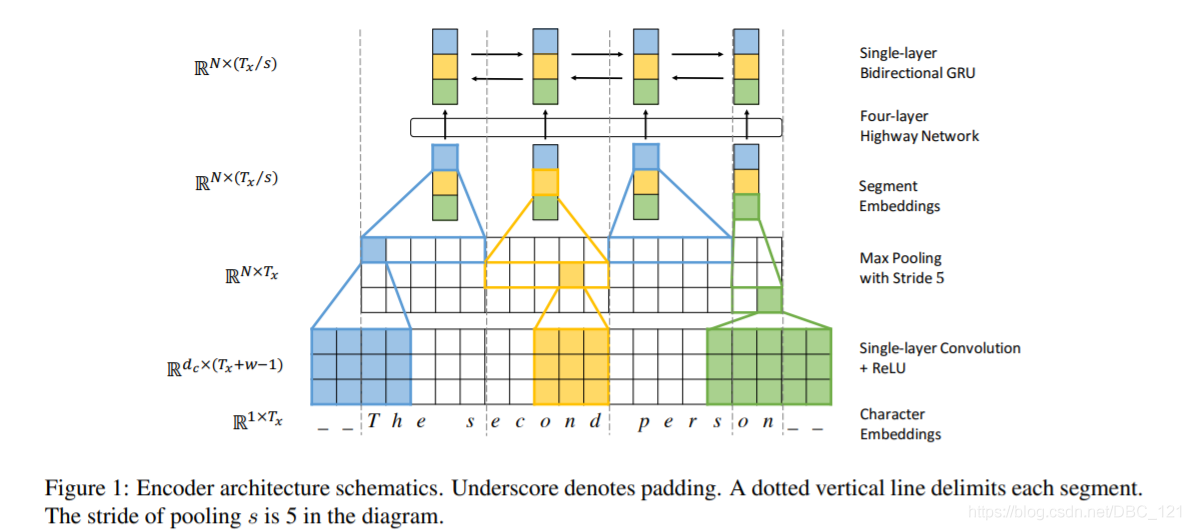
- Character-level to build word-level:该网络结构主要是对字符进行卷积以生成单词嵌入,同时使用固定窗口对PoS标记的字嵌入进行操作。
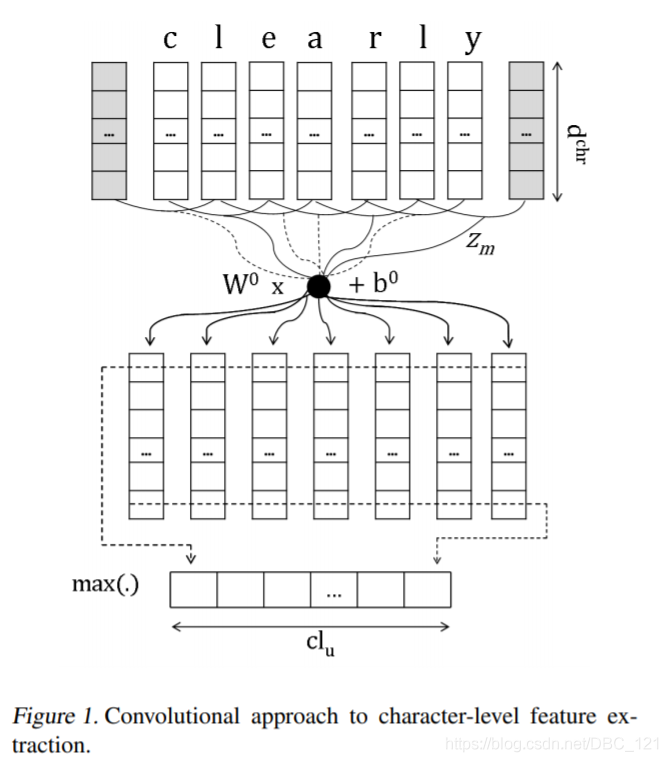
- Character-Aware Neural Language Models:这是一个更加复杂的方法,其主要动机在于:提供一种功能强大,功能强大的语言模型,可以在各种语言中有效。其可编码子词相关性:eventful, eventfully, uneventful。同时解决先前模型的罕见字问题,使用更少的参数获得可比较的表现力。
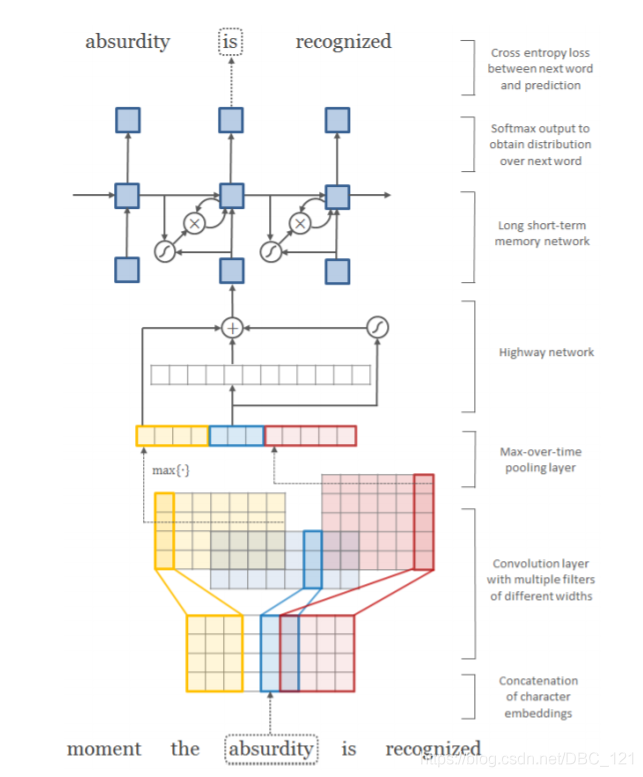
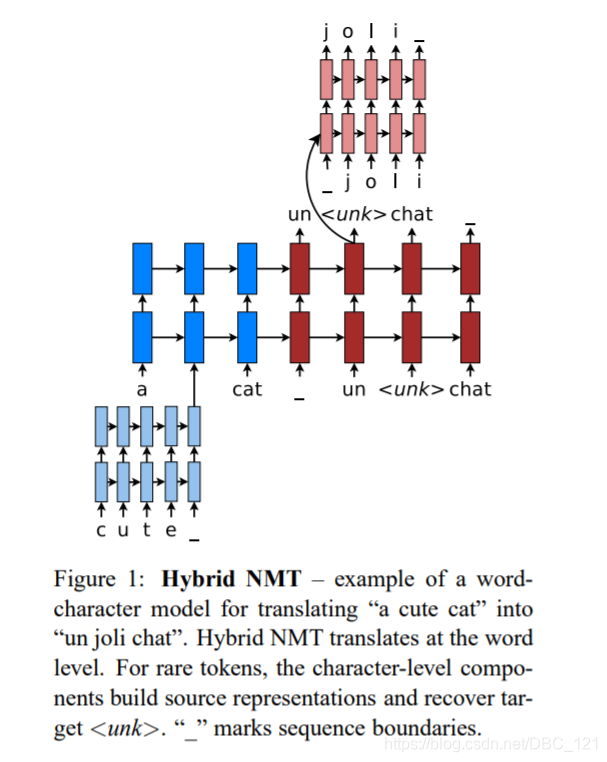
- Hybrid NMT(https://arxiv.org/pdf/1604.00788.pdf):这是一个非常出色的框架,主要是在单词级别进行翻译,但是在有需要的时候可以很方便的使用字符级别的输入。
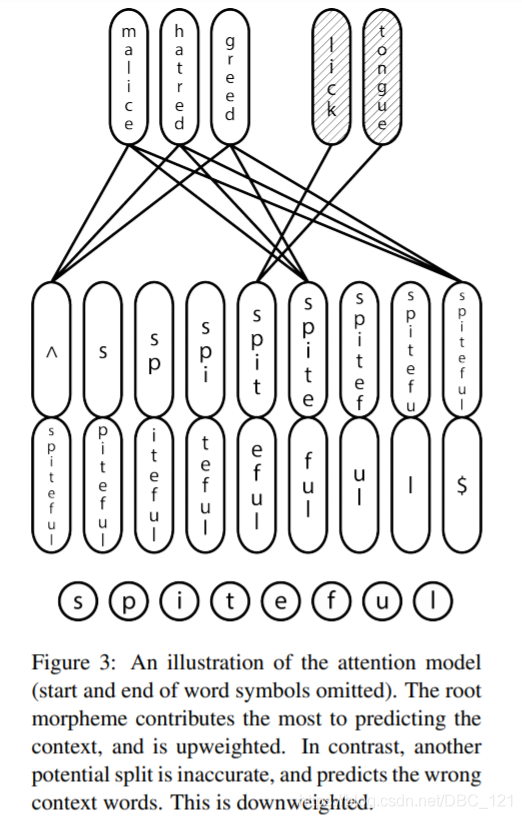
- chars for word embeddings:该模型的目标与word2vec相同,但是使用的时字符集别的输入。它使用了双向的LSTM结构尝试捕获形态并且能够推断出词根。
- Enriching Word Vectors with Subword Information:它是word2vec的升级版,对于具有大量形态学的稀有词和语言有更好的表征,它也可以说是带有字符n-gram的w2v skip-gram模型的扩展。
参考资料: