前言
标题:Massive Exploration of Neural Machine Translation Architectures
原文链接:Link
Github:NLP相关Paper笔记和代码复现
说明:阅读论文时进行相关思想、结构、优缺点,内容进行提炼和记录,论文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
介绍
在计算机视觉中通常会在大型超参数空间中进行扫描,但对于NMT模型而言,这样的探索成本过高,从而限制了研究人员完善的架构和超参数选择。更改超参数成本很大,在这篇论文中,展示了以NMT架构超参数为例的首次大规模分析,实验为构建和扩展NMT体系结构带来了新颖的见解和实用建议。本文工作探索NMT架构的常见变体,并了解哪些架构选择最重要,同时展示所有实验的BLEU分数,perplexities,模型大小和收敛时间,包括每个实验多次运行中计算出的方差数。论文主要贡献如下:
- 展示了以NMT架构超参数为例的首次大规模分析,实验为构建和扩展NMT体系结构带来了新颖的见解和实用建议。例如,深层编码器比解码器更难优化,密度残差连接比常规的残差连接具有更好的性能,LSTM优于GRU,并且调整好的BeamSearch对于获得最新的结果至关重要。
- 确定了随机初始化和细微的超参数变化对指标(例如BLEU)的影响程度,有助于研究人员从随机噪声中区分出具有统计学意义的结果。
- 发布了基于TensorFlow的开源软件包,该软件包专为实现可再现的先进sequence-to-sequence模型而设计。
本篇论文使用的sequence-to-sequence结构如下,对应的编号是论文中章节阐述部分。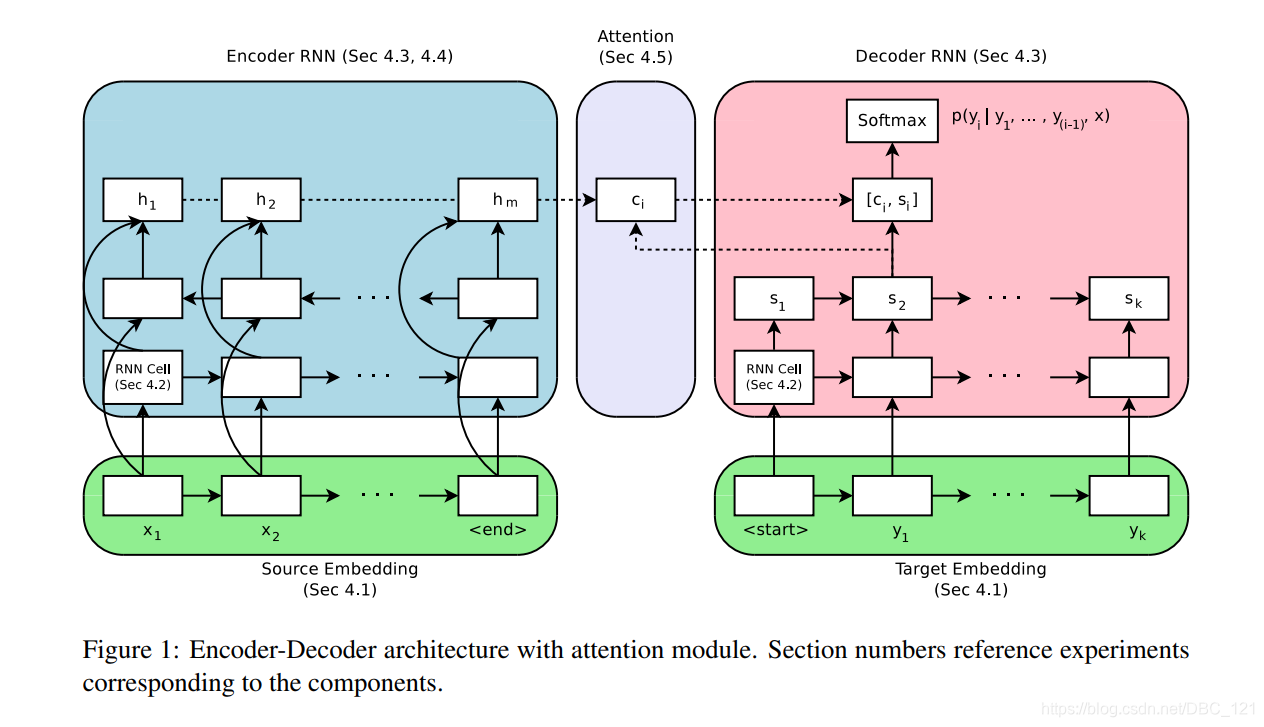
编码器方法 $f_{enc}$ 将 $x=(x_1,…,x_m)$ 的源tokens序列作为输入,并产生状态序列 $h=(h_1,…,h_m)$。在base model中, $f_{enc}$ 是双向RNN,状态 $h_i$ 对应于由后向RNN和前向RNN的状态的concatenation,$h_i = [\overrightarrow{h_i};\overleftarrow{h_i}]$。解码器 $f_{dec}$ 是RNN,可根据 $h$ 预测目标序列 $y =(y_1,…,y_k)$ 的概率。根据解码器RNN中的循环状态 $s_i$、前一个单词 $y_{<i}$ 和上下文向量 $c_i$ 预测每个目标token $y_i\in 1,…V$ 的概率。上下文向量 $c_i$ 也称为attention向量,并计算为源状态的加权平均值。
$$c_i=\sum_{j}a_{ij}h_j$$ $$a_{ij}=\frac{\hat{a}{ij}}{\sum_j\hat{a}_{ij}}$$ $$\hat{a}{ij}=att(s_i,h_j)$$
这里的 $att(s_i,h_j)$用于计算编码器状态 $h_j$ 和解码器状态 $s_i$ 之间的unnormalized alignment score。在base model中,使用 $att(s_i,h_j)= \left \langle W_hh_j,W_ss_i\right \rangle$,其中矩阵 $W$ 用于将源状态和目标状态转换为相同大小的表示形式。解码器输出固定大小为 $V$ 的词汇表上的分布。
$$P(y_i|y_1,…,y_{i-1},x)=softmax(W[s_i,c_i]+b)$$
通过使用随机梯度下降来最小化目标词的负对数似然性来对整个模型进行end-to-end训练。
在以下每个实验中,除了要研究的一个超参数外,基线模型的超参数都保持恒定。以此避免各种超参数更改的影响。当然,此过程并未考虑到超参数之间的相互作用,所以当作者认为这种相互作用很可能发生时,进行了额外的实验。
实验结果
论文为了简洁起见,在下面的表中仅报告均值BLEU,标准差,括号中的最高BLEU和模型大小。
Embedding维数
我们期望更大的嵌入维数得到更好的BLEU得分,或者至少降低perplexities,但是作者发现情况并非总是如此,下表显示了2048维嵌入效果总体上最佳,但是提升的幅度很小。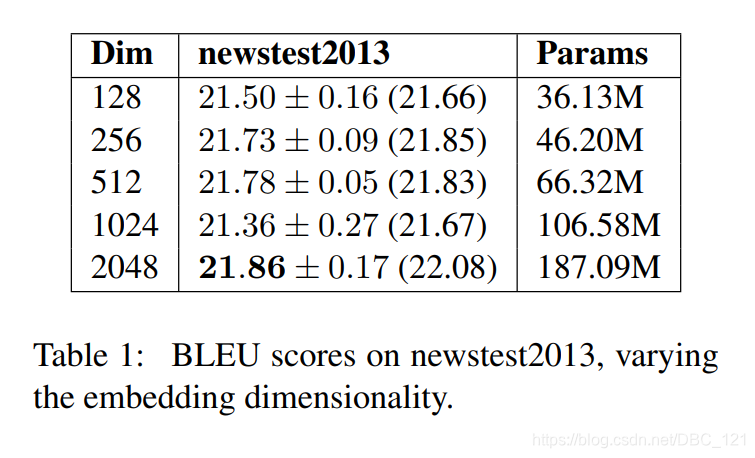
表中发现甚至很小的128维嵌入效果也出乎意料地出色,而收敛速度几乎快一倍。
结论
- 嵌入维数的大小对梯度更新没有显着差异,并且无论大小如何,对嵌入矩阵的梯度更新的范数在整个训练过程中大致保持恒定。
- 没有观察到较大嵌入维数的过度拟合,并且在整个实验中训练的log
perplexity大致相等,这表明该模型没有有效利用额外的参数,可能需要更好的优化技术。
RNN Cell Variant
我们使用诸如GRU和LSTM之类的门控单元的动机是梯度消失问题,而使用vanilla RNN(序列分析)单元,深度网络无法通过多层和时间步长有效地传播信息和梯度。对于基于注意力的模型,作者认为解码器应该几乎能够完全基于当前输入和注意力上下文做出决策。我们始终将解码器状态初始化为零而不是传递编码器状态,这一事实支持了这一假设,这意味着解码器状态不包含有关编码源的信息。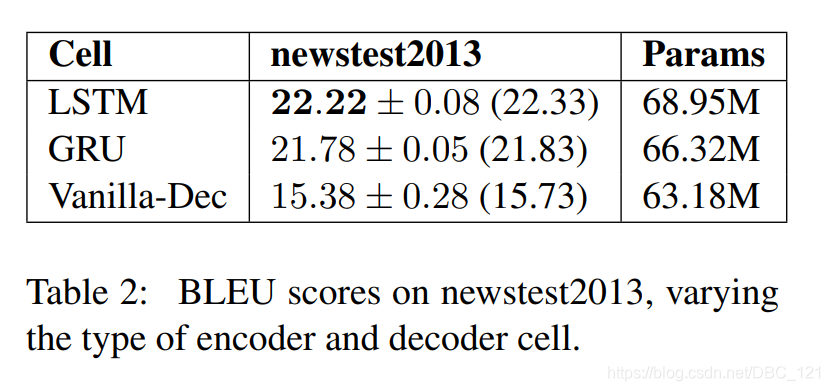
结论
- 实验中,LSTM单元始终优于GRU单元,但由于softmax的原因,没有观察到两者之间在训练速度上存在较大差异。
- Vanilla-Dec无法像门控变体单元一样学习。这表明解码器确实在多个时间步长中通过其自己的状态传递信息,而不是仅依赖于注意力机制和当前输入。
Encoder 和 Decoder 的深度
一般而言,我们希望更深层的网络能比更浅层的网络表现更好。但先前的研究结果没有支撑这一结论,所以作者探讨了多达8层编码器和解码器在深度方面的影响。对于更深的网络,作者还尝试了两种残差连接的形式,以刺激梯度传播。作者在连续的层之间插入残差连接,当 $h_t^{(l)}(x_t^{(l)},h_{t-1}^{(l)})$ 是 $l$ 层RNN在 $t$ 步的输入,则:
$$x_t^{(l+1)}=h_t^{(l)}(x_t^{(l)},h_{t-1}^{(l)})+x_t^{(l)}$$
其中,$x_t^{(0)}$ 输入token的词嵌入。除此之外,还尝试另一种残差连接的变体,在此变体中,添加了从每一层到所有其他层的skip connections(跳跃连接,作用是在比较深的网络中,解决在训练的过程中 梯度爆炸 和 梯度消失 问题)
$$x_t^{(l+1)}=h_t^{(l)}(x_t^{(l)},h_{t-1}^{(l)})+\sum_{j=0}^lx_t^{(j)}$$
下表显示了在有和没有残差连接的情况下改变编码器和解码器深度的结果: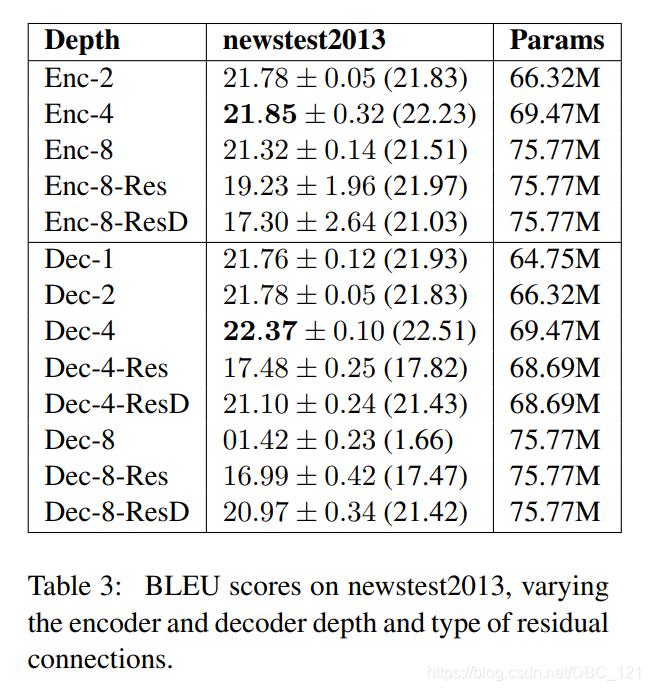
结论
- 没有明显的证据表明编码器深度必须超过两层,但发现具有残余连接的更深的模型在训练过程中发散的可能性更大。
- 对于解码器而言,如果没有残差连接,不可能训练8层及以上的网络
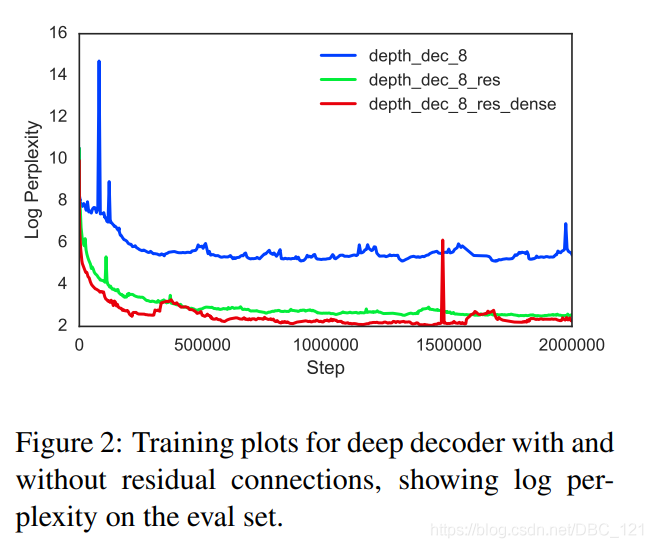
- 在整个深度解码器实验中,密度残差连接始终优于常规残差连接,并且在步数方面收敛得更快,如下图所示:
单向与双向编码器
在这组实验中,探索了有无源输入的反向序列的单向编码器,因为这是一种常用技巧,它使编码器可以为较早的单词创建更丰富的表示形式。下表显示了双向编码器通常优于单向编码器,但差距不大: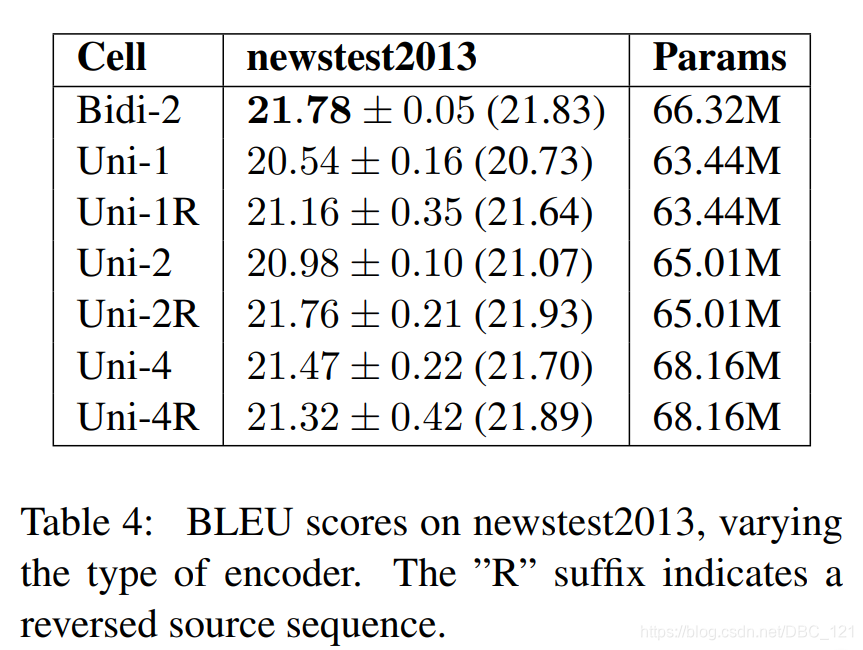
结论
- 具有反向源输入的编码器始终优于其非反向源输入的编码器,但比较浅的双向编码器效果差。
注意力机制
两种最常用的注意力机制分别是加法式的Bahdanau注意力和乘法式的Luong注意力,公式分别如下:
$$score(h_j,s_i)=\left \langle v,tanh(W_1h_j+W_2s_i) \right \rangle$$ $$score(h_j,s_i)=\left \langle W_1h_j,W_2s_i \right \rangle$$
我们将 $W_1h_j$ 和 $W_2s_i$ 的维数称为“注意维数”,并通过更改层大小将其从128更改为1024。作者还通过使用最后一个编码器状态初始化解码器状态(None-State),或将最后一个解码器状态与每个解码器输入连接来使用无注意机制(None-Input)进行实验,结果如下: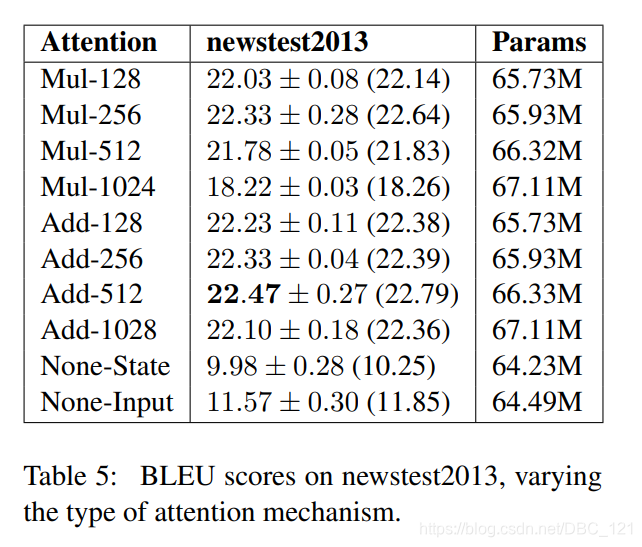
结论
- 加法式注意机制略微但始终优于乘法式注意力机制,而注意维数的影响很小。
- “Non-Input”表现很差,因为它们在每个时间步都可以访问编码器信息。
- 发现在整个训练过程中,基于注意力的模型对解码器状态表现出明显更大的梯度更新。
Beam Search策略
下表显示了改变Beam Search大小和增加长度归一化惩罚的影响: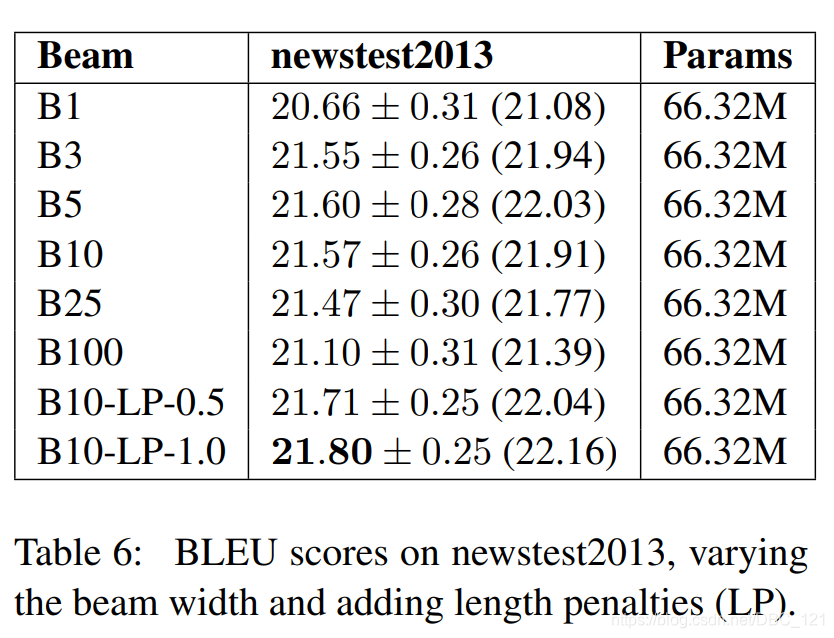
结论
- 即使有长度损失,很大的Beam Search性能也比较小的Beam Search差,所以选择正确的Beam Search大小对于获得最佳结果至关重要。
- 发现非常大的beam大小会产生较差的结果,并且存在最佳beam大小。
系统比较
最后,作者将在newstest2013验证集上选择的所有实验中性能最佳的模型(具有512维加法式注意力的base model)与下表中其他模型的历史结果进行了比较。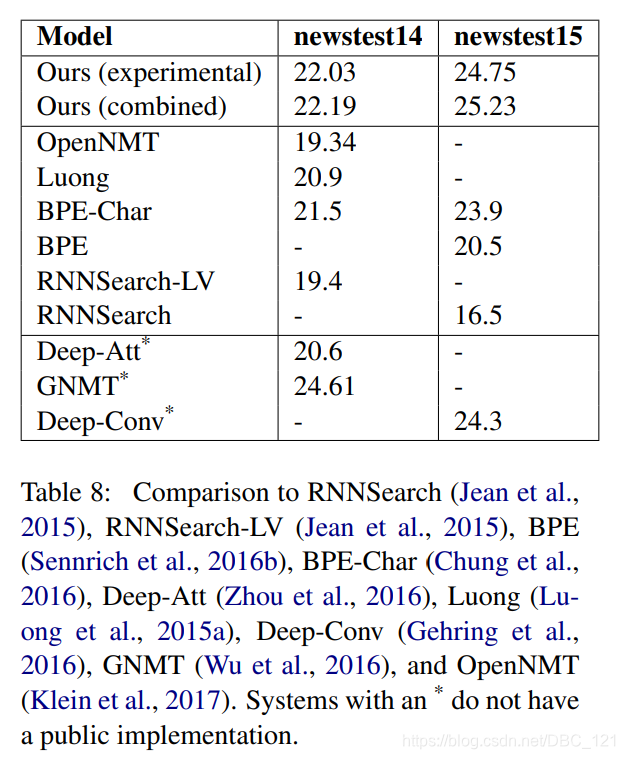
下表是综合了所有hyperparameter的最佳方案配置:
总结
在这篇论文中,展示了以NMT架构超参数为例的首次大规模分析,实验为构建和扩展NMT体系结构带来了新颖的见解和实用建议。总结以上的重要结论如下:
- 2048维的嵌入维度效果最佳,但提升幅度很小,即使嵌入维度为128也似乎有足够的能力来捕获大多数必要的语义信息。
- LSTM单元始终优于GRU单元
- 具有2至4层的双向编码器效果最佳,对于更深的编码器训练起来更加不稳定,但是如果可以很好地优化它们,则有着很好的潜力。
- 深度为4层的解码器略胜于浅层解码器。残差连接对于训练具有8层解码器是必需的,而密集的残差连接则提供了额外的鲁棒性。
- 加法式注意力机制产生了总体最佳结果。
- 表现良好的Beam Search使用长度惩罚是至关重要的,beam大小为5到10,长度惩罚为1.0似乎效果很好。