前言
标题:A Comparative Study on Transformer vs RNN in Speech Applications
原文链接:Link
Github:NLP相关Paper笔记和代码复现
说明:阅读论文时进行相关思想、结构、优缺点,内容进行提炼和记录,论文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
介绍
序列到序列模型已广泛用于端到端语音处理中,例如自动语音识别(ASR),语音翻译(ST)和文本到语音(TTS)。本文着重介绍把Transformer应用在语音领域上并与RNN进行对比。与传统的基于RNN的模型相比,将Transformer应用于语音的主要困难之一是,它需要更复杂的配置(例如优化器,网络结构,数据增强)。在语音应用实验中,论文研究了基于Transformer和RNN的系统的几个方面,例如,根据所有标注数据、训练曲线和多个GPU的可伸缩性来计算单词/字符/回归错误。本文的几个主要贡献:
- 将Transformer和RNN进行了大规模的比较研究,尤其是在ASR相关任务方面,它们具有显着的性能提升。
- 提供了针对语音应用的Transformer的训练技巧:包括ASR,TTS和ST
- 在开放源代码工具包ESPnet中提供了可复制的端到端配置和模型,这些配置和模型已在大量可公开获得的数据集中进行了预训练。
端到端RNN
如下图中,说明了实验用于ASR,TTS和ST任务的通用S2S结构。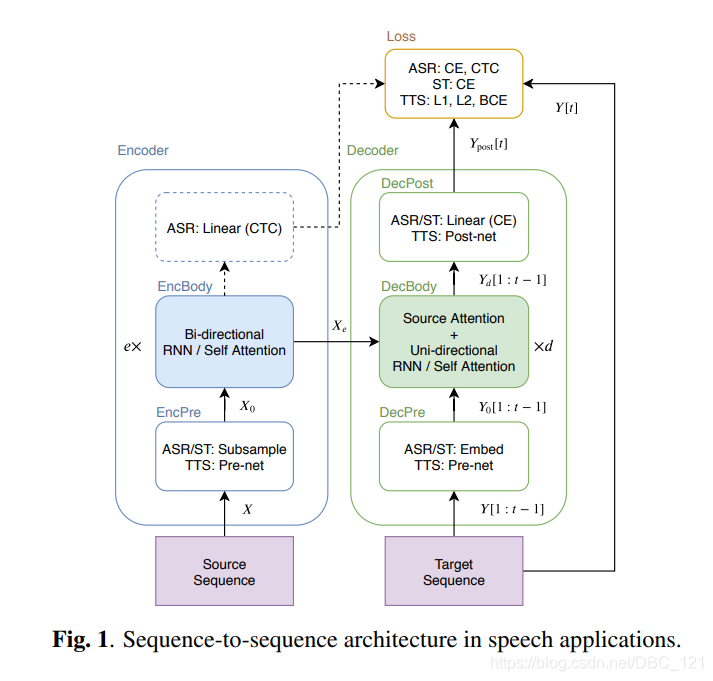
S2S包含两个神经网络:其中编码器如下:
$$(1):X_0=EncPre(X)$$ $$(2):X_e=EncBody(X_0)$$
解码器如下:
$$(3):Y_0[1:t-1]=DecPre(Y[1:t-1])$$ $$(4):Y_d[t]=DecBody(X_e,Y_0[1:t-1])$$ $$(5):Y_{post}[1:t]=DecPost(Y_d[1:t])$$
其中 $X$ 是源序列,例如,语音特征序列(对于ASR和ST)或字符序列(对于TTS),$e$ 是EncBody层数,$d$ 是DecBody中的层数,$t$ 是目标帧索引,以上等式中的所有方法均由神经网络实现。对于解码器输入 $Y [1:t − 1]$,我们在训练阶段使用一个真实标注的前缀,而在解码阶段使用一个生成的前缀。在训练过程中,S2S模型学习是将在生成的序列 $Y_{post}$ 和目标序列 $Y$ 之间标量损失值最小化:
$$(6):L=Loss(Y_{post},Y)$$
本节的其余部分描述了基于RNN的通用模块:“EncBody”和“DecBody”。而将“EncPre”,“DecPre”,“DecPost”和“Loss”视为特定于任务的模块,我们将在后面的部分中介绍。
等式(2)中的EncBody将源序列 $X_0$ 转换为中间序列 $X_e$,现有的基于RNN的EncBody实现通常采用双向长短记忆(BLSTM)。对于ASR,编码序列 $X_e$ 还可以在进行联合训练和解码中,用基于神经网络的时序类分类(CTC)进行逐帧预测。
等式(4)中的DecBody()将生成具有编码序列 $X_e$ 和目标前缀 $Y_0 [1:t − 1]$ 的前缀的下一个目标帧。对于序列生成,解码器通常是单向的。 例如,具有注意力机制的单向LSTM通常用于基于RNN的DecBody()实现中。该注意力机制计算逐帧权重,以将编码后的帧 $X_e$ 求和,并作为要以前缀 $Y0 [0:t-1]$ 进行转换的逐帧目标向量,我们称这种注意为“encoder-decoder attention”
Transformer
Transformer包含多个dot-attention层:
$$(7):att(X^q,X^k,X^v)=softmax(\frac{X^qX^{kT}}{\sqrt{d^{att}}})X^v$$
其中 $X^k,X^v\in \mathbb{R}^{n^k\times d^{att}}$ 和 $X^q\in \mathbb{R}^{n^q\times d^{att}}$ 是attention层的输入,$d^{att}$是特征维数,$n^q$是 $X^q$ 的长度,$n^k$ 是 $X^k$ 和 $X^v$ 的长度。我们将 $X^qX^{kT}$ 称为“attention matrix”。多头注意力机制如下:
$$(8):MHA(Q, K, V )=[H_1,H_2,…,H_{d^{head}}]W^{head}$$ $$(9):H_h=att(QW_h^q,KW_h^k,VW_h^v)$$
其中, $K,V \in \mathbb{R}^{n^k\times d^{att}}$ 和 $Q\in \mathbb{R}^{n^q\times d^{att}}$ 是 $MHA$ 层的输入,$H_h\in \mathbb{R}^{n^q\times d^{att}}$ 是第 $h$ 个attention层的输出$(h =1,…,dhead )$。$W_h^q,W_h^k,W_h^v \in \mathbb{R}^{d^{att}\times d^{att}}$和 $W^{head} \in \mathbb{R}^{d^{att}d^{head}\times d^{att}}$ 是可学习的权重矩阵,而 $d^{head}$ 是该层中的注意力头数。
我们定义用于等式(2)的基于Transformer的EncBody(),如下所示:
$$(10):X_i^{‘}=X_i+MHA_i(X_i,X_i,X_i)$$ $$X_{i+1}=X_i^{‘}+FF_i(X_i^{‘})$$
其中 $i = 0,…,e − 1$ 是编码器层的索引,而 $FF_i$ 是第 $i$ 个两层前馈网络。
$$(12):FF(X[t])=ReLU(X[t]W_1^{ff}+b_1^{ff})W_2^{ff}+b_2^{ff}$$
其中 $X[t]\in \mathbb{R}^{d^{att}}$ 是输入序列 $X$ 的第 $t$ 帧,$W_1^{ff} \in \mathbb{R}^{d^{att}\times d^{ff}},W_2^{ff} \in \mathbb{R}^{d^{ff}\times d^{att}}$ 是可学习的权重矩阵,$b_1^{ff}\in \mathbb{R}^{d^{ff}},b_2^{ff}\in \mathbb{R}^{d^{att}}$ 是可学习的偏差向量。等式(10)中的 $MHA_i(X_i,X_i,X_i)$ 为“self-attention”
用于等式(4)的基于Transformer的DecBody()包含两个attention模块:
$$(12):Y_j[t]^{‘}=Y_j[t]+MHA_j^{self}(Y_j[t],Y_j[1:t],Y_j[1:t])$$ $$Y_j[t]^{‘’}=Y_j+MHA_j^{src}(Y_j^{‘},X_e,X_e)$$ $$Y_{j+1}=Y_j^{‘’}+FF_j(Y_j^{‘’})$$
其中 $j = 0,…,d − 1$ 是解码器层的索引,我们将 $MHA_j^{src}(Y_j^{‘},X_e,X_e)$ 中的解码器输入与编码器输出之间的attention矩阵称为“encoder-decoder attention”。因为单向解码器对于序列生成很有用,所以它在第 $t$ 个目标帧处的attention矩阵被屏蔽,因此它们不会与 $t$ 之后的帧进行连接。可以使用带有三角形二进制矩阵的元素乘积并行地进行序列mask。 因为它不需要顺序操作,所以它提供了比RNN更快的实现。
Transformer采用正弦位置编码:
$$PE[t]=\left{\begin{matrix} sin\frac{t}{10000^{t/d^{att}}} & 当t是偶数\ cos\frac{t}{10000^{t/d^{att}}} & 当t是奇数 \end{matrix}\right.$$
在EncBody()和DecBody()模块之前,输入序列 $X_0,Y_0$ 与($PE[1],PE[2],…$)串联在一起。
Transformer应用于ASR
S2S从log-mel滤波器组语音特征的输入序列 $X^{fbank}$ 预测字符或SentencePiece的目标序列 $Y$。ASR中的源 $X$ 表示为具有音高特征的83维log-mel滤波器阵列帧的序列。首先,EncPre()通过使用具有256维,步长为2且内核大小为3的两层CNN或类似于VGG的最大池化的两层CNN,将源序列 $X$ 转换为子采样序列 $X_0\in \mathbb{R}^{n^{sub}\times d^{att}}$,其中 $n^{sub}$ 是CNN输出序列的长度。然后,EncBody()将 $X_0$ 转换为CTC和解码器的一系列编码特征 $X_e\in \mathbb{R}^{n^{sub}\times d^{att}}$。
解码器接收编码序列 $X_e$ 和目标序列 $Y[1:t-1]$:字符或SentencePiece。首先,等式(3)中的DecPre()将,进行词嵌入。接下来,DecBody()和单线性层DecPost()在给定 $X_e$ 和目标序列 $Y[1:t-1]$ 的情况下,预测下一个token,即 $Y_{post}[t]$ 的后验分布。解码器和CTC模块的后验分布预测为:$p_{s2s}(Y|X)$和 $p_{ctc}(Y|X)$,训练阶段两个loss加权求和:
$$L^{ASR}=-alogp_{s2s}(Y|X)-(1-a)logp_{ctc}(Y|X)$$
In the decoding stage, the decoder predicts the next token given the speech feature X and the previous predicted tokens using beam search, which combines the scores of S2S, CTC and the RNN language model (LM)
解码阶段除了ctc和s2s以外还需要一个语言模型
$$\hat{Y}=argmax{\lambda logp_{s2s}(Y|X_e)+(1-\lambda)logp_{ctc}(Y|X_e)+\gamma logp_{lm}(Y)}$$
Transformer应用于TTS
TTS中编码器的输入是包含EOS符号的token序列,首先,将token序列进行词嵌入,然后将通过权重参数缩放的位置编码添加到向量中,即等式(1)的EncPre()实现。随后,等式(2)中的编码器EncBody()将这个输入序列转换为解码器的编码特征序列。TTS中解码器的输入是一系列编码器特征和log-mel滤波器组特征。在训练中,标记数据log-mel滤波器组特征以teacher forcing方式使用,而推理中,预测特征以自回归方式使用。
解码器中,作为等式(3)中的DecPre()的TTS实现,Prenet将80维log-mel滤波器组特征的目标序列转换为隐藏特征序列。该网络由两个具有256个单位的线性层,一个ReLU激活函数和一个dropout组成,后面是具有 $d^{att}$ 单位的投影线性层。然后在等式(4)中的解码器DecBody(),其架构与编码器相同,将编码器特征和隐藏特征的序列转换为解码器特征的序列。对 $Y_d$ 的每一帧应用两个线性层以分别计算目标特征和EOS的概率。最后,将Postnet应用于预测目标特征的序列。Postnet是一个五层的CNN,其每一层都是一维卷积,具有256个通道,内核大小为5,然后进行批量归一化,tanh激活函数和dropout。这些模块是等式(5)中DecPost()的TTS实现。
在TTS训练中,优化了整个网络,以最大程度地减少TTS中的两个损失功能。
- 目标特征的L1损失
- EOS概率的二元交叉熵(BCE)损失
- guided attention loss
为了解决BCE计算中类别不平衡的问题,对正样本使用恒定权重。除此之外,作者表示没有引入任何超参数来平衡这三个损耗值。推理中,模型以自回归方式预测下一帧的目标特征,并且如果EOS的概率变得高于某个阈值(例如0.5),则模型将停止预测。
ASR相关的实验以及调参方法
下表中,作者总结了在ASR实验中使用的15个数据集:
实验配置如下:
除了最大的LibriSpeech($d^{head}= 8,d^{att} = 512$)外,我们对每个语料库的Transformer采用了相同的架构配置($e = 12,d = 6,d^{ff} = 2048,d^{head} = 4,d^{att} = 256$)。
- Transformer更快收敛
Transformer requires a different optimizer configuration from RNN because Transformer’s training iteration is eight times faster and its update is more fine-grained than RNN.
- 参方法主要参考之前论文方法,参数是最后10个epoch的模型的求平均
To train Transformer, we basically followed the previous literature (e.g., dropout, learning rate, warmup steps). We did not use development sets for early stopping in Transformer. We simply ran 20 – 200 epochs (mostly 100 epochs) and averaged the model parameters stored at the last 10 epochs as the final model.
- 解码阶段Transformer和RNN用相同的配置。
In the decoding stage, Transformer and RNN share the same configuration for each corpus, for example, beam size (e.g., 20 – 40), CTC weight λ (e.g., 0.3), and LM weight γ (e.g., 0.3 – 1.0)
如下表中展示根据每个语料库的字符/单词错误率(CER / WER)的ASR结果,非常好的实验结果:
从图中我们可以得出结论:
- Transformer更大的minibatch效果更好
We observed that Transformer trained with a larger minibatch became more accurate while RNN did not.
- 8倍速于RNN
In this task, Transformer achieved the best accuracy provided by RNN about eight times faster than RNN with a single GPU.
下表总结了LibriSpeech ASR基准,因为它是最具竞争力的任务之一。
下图显示了在LibriSpeech上使用多个GPU获得的ASR训练曲线:
训练技巧:
- 扩大minibatch的大小
- 使用accumulating gradient strategy
- 使用dropout
- 使用数据增强方法可以在很大程度上提升性能
- 解码阶段RNN和Transformer在相同参数集上性能都比较好
下图清楚地表明,在9种语言中,Transformer明显优于RNN:
TTS中Transformer的配置为:$e=6, d=6, d^{att}=384, d^{ff}=1536, d^{head}=4$,且系统的输入都是字符序列。下面两个图显示了两个语料库中的训练曲线:
下面两个图展示了生成的语音频谱图

总结
把Transformer应用在语音领域上与RNN对比的论文,结果也是比较喜人,重点是它在ESPnet上面开源了,模型、代码都给出来了,还给出了各种训练方法和技巧,是一篇实用性很强的文章。