前言
Github:本文代码放在该项目中:NLP相关Paper笔记和代码复现
说明:讲解时会对相关文章资料进行思想、结构、优缺点,内容进行提炼和记录,相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
对于TensorFlow或者Pytorch,可能很多小伙伴已经使用它执行了很多模型任务了,但是回过头来仔细想想,对于这些计算框架中的计算图可能还一知半解,没有好好理解研究过,这篇文章就来捋一捋计算图,这毕竟是Tensorflow和Pytorch这样的深度学习计算框架非常重要的概念。
写在前面
无论是机器学习也好,还是深度学习也好,都是围绕着数学建模以及数学运算进行的,在这样的背景之下,诞生了许多的计算框架,我们所熟知的TensorFlow和Pytorch就是其中的主流,这些计算框架以计算服务为根本,自然需要一个计算模型。如果接触过开发的小伙伴就能体会到,这些计算框架的编程方式有着很大的差异。无论是编译类型的语言还是脚本语言,都是一步一步的计算变量, 从而得到结果,比如result = input1 + input2,当执行完语句后,就会得到result的值。
而TensorFlow和Pytorch则不一样,首先需要通过编程构建一个计算图,然后将数据作为输入,通过这个计算图规定的计算操作进行计算,最后得到计算结果。这种符号式编程有着较多的嵌入和优化,性能也随之提升。同时计算图非常适合用来思考数学表达式,举个例子,比如计算 $e=(a+b)*(b+1)$,在这个式子中存在两个加法和一个乘法的运算,为了更加方便我们讨论,我们引入中间变量来给每个运算的输出表示为一个变量,如下:
$$c=a+b$$ $$d=b+1$$ $$e=c∗d$$
接下来,我们来构建计算图,我们将所有这些操作放入节点中,并同时计算出计算结果,如下: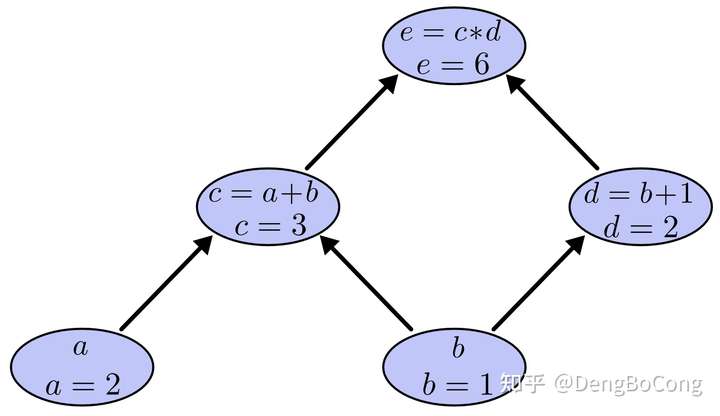
我们可以清晰的看到运算表达式中,各个运算操作以及变量间的依赖和调用关系。 接着我们来求边的偏导数,如下: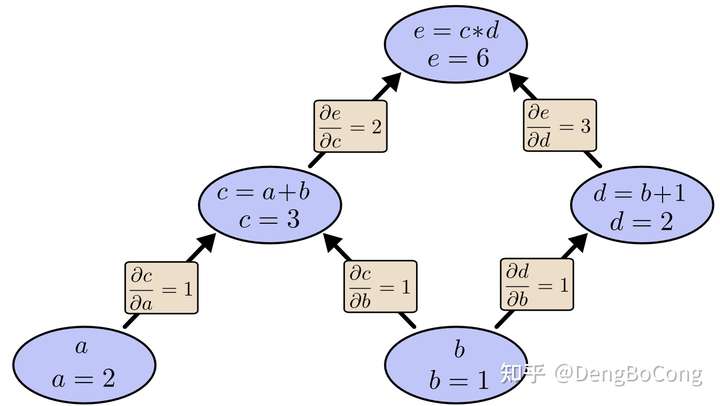
通过链式法则,我们逐节点的计算偏导数,在网络backward时候,需要用链式求导法则求出网络最后输出的梯度,然后再对网络进行优化。类似上图的表达形式就是TensorFlow以及Pytorch的基本计算模型。总结而言,计算图模型由节点(nodes)和线(edges)组成,节点表示操作符Operator,或者称之为算子,线表示计算间的依赖,实线表示有数据传递依赖,传递的数据即张量,虚线通常可以表示控制依赖,即执行先后顺序。
计算图从本质上来说,是TensorFlow在内存中构建的程序逻辑图,计算图可以被分割成多个块,并且可以并行地运行在多个不同的cpu或gpu上,这被称为并行计算。因此,计算图可以支持大规模的神经网络,如下: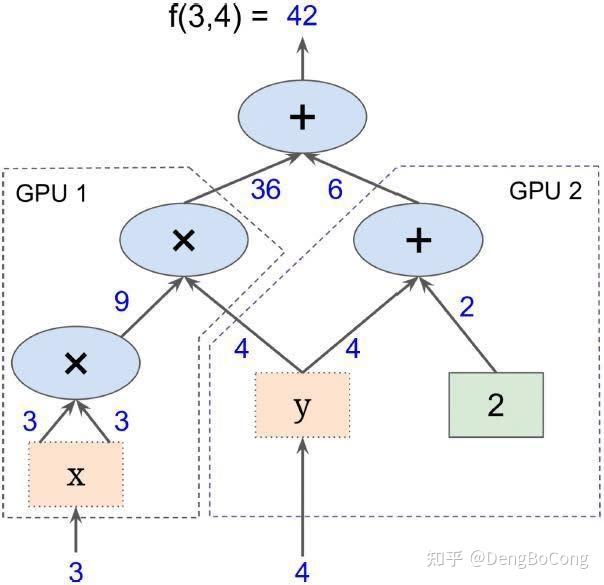
Tensorflow中的计算图
TensorFlow中的计算图有三种,分别是静态计算图,动态计算图,以及Autograph,目前TensorFlow2默认采用的是动态计算图,即每使用一个算子后,该算子会被动态加入到隐含的默认计算图中立即执行得到结果(在TensorFlow1中,采用的是静态计算图,需要先使用TensorFlow的各种算子创建计算图,然后再开启一个会话Session,显式执行计算图)。对于动态图的好处显而易见,它方便调试程序,让TensorFlow代码的表现和Python原生代码的表现一样,写起来就像写numpy一样,各种日志打印,控制流全部都是可以使用的,当然,这相对于静态图来讲牺牲了些效率,因为使用动态图会有许多次Python进程和TensorFlow的C++进程之间的通信,而静态计算图构建完成之后几乎全部在TensorFlow内核上使用C++代码执行,效率更高。此外静态图会对计算步骤进行一定的优化,剪去和结果无关的计算步骤。
如果需要在TensorFlow2.0中使用静态图,可以使用@tf.function装饰器将普通Python函数转换成对应的TensorFlow计算图构建代码。运行该函数就相当于在TensorFlow1.0中用Session执行代码,使用tf.function构建静态图的方式叫做 Autograph。
- 静态计算图:一种比较早先使用静态计算图的方法分两步,第一步定义计算图,第二步在会话中执行计算图,如下展示了TensorFlow1.0和TensorFlow2.0的写法(可以调用tf.global_variables_initializer去初始化变量或者通过tf.control_dependencies去执行计算图中没有包含的节点):
1 | import tensorflow as tf |
- 动态计算图:动态计算图已经不区分计算图的定义和执行了,而是定义后立即执行,因此称之为 Eager Excution。对于上面的操作,我们可以直接如下面代码的第一部分那样直接使用,也可以将使用动态计算图代码的输入和输出关系封装成函数,如下:
1 | # 第一部分 |
- Autograph:动态计算图运行效率相对较低,可以用@tf.function装饰器将普通Python函数转换成和TensorFlow1.0对应的静态计算图构建代码。在TensorFlow1.0中,使用计算图分两步,第一步定义计算图,第二步在会话中执行计算图。在TensorFlow2.0中,如果采用Autograph的方式使用计算图,第一步定义计算图变成了定义函数,第二步执行计算图变成了调用函数。不需要使用会话了,一切都像原始的Python语法一样自然。实践中,我们一般会先用动态计算图调试代码,然后在需要提高性能的的地方利用@tf.function切换成Autograph获得更高的效率,如下(这就是为什么我们上面第二部分封装成函数的原因):
1 | # 使用autograph构建静态图 |
@tf.function
需要注意的是不是所有的函数都可以通过tf.function进行加速的,有的任务并不值得将函数转化为计算图形式,比如简单的矩阵乘法,然而,对于大量的计算,如对深度神经网络的优化,这一图转换能给性能带来巨大的提升。我们也把这样的图转化叫作tf.AutoGraph,在Tensorflow 2.0中,会自动的对被@tf.function装饰的函数进行AutoGraph优化。下面我们来看看被tf.function装饰的函数第一次执行时都做了什么:
- 函数被执行并且被跟踪(tracing),Eager execution处于关闭状态,所有的Tensorflow函数被当做tf.Operation进行图的创建。
- AutoGraph被唤醒,去检测Python代码可以转为Tensorflow的逻辑,比如while > tf.while, for > tf.while, if > tf.cond, assert > tf.assert。
- 通过以上两步,对函数进行建图,为了保证Python代码中每一行的执行顺序,tf.control_dependencies被自动加入到代码中,保证第i行执行完后我们会执行第i+1行。
- 返回tf.Graph,根据函数名和输入参数,将这个graph存到一个cache中。
- 对于任何一个该函数的调用,我们会重复利用cache中的计算图进行计算。
我们来看一下Tensorflow 2.0中Eager Execution的代码如何转为tf.function的代码,首先来看一段简单的Tensorflow 2.0代码:
1 | def f(): |
因为Tensorflow 2.0默认是Eager execution,代码的阅读和执行就和普通的Python代码一样,简单易读。首先我们简单的加上@tf.function装饰一下,为了方便调试,我们加入一个print和一个tf.print,如下:
1 |
|
这里有个异常,为什么?因为tf.function可能会对一段Python函数进行多次执行来构图,在多次执行的过程中,同样的Variable被创建了多次,产生错误。这其实也是一个很容易混乱的概念,在eager mode下一个Variable是一个Python object,所以会在执行范围外被销毁,但是在tf.function的装饰下,Variable变成了tf.Variable,是在Graph中持续存在的。所以,把一个在eager mode下正常执行的函数转换到Tensorflow图形式,需要一边思考着计算图一边构建程序。
参考资料: