前言
标题:CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset
原文链接:Link
Github:NLP相关Paper笔记和实现
说明:阅读论文时进行相关思想、结构、优缺点,内容进行提炼和记录,论文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
最近在搜集一些对话数据集,众所周知,生成对话数据集是一件费钱又费时的工作,所以一般只有大机构才能做出高质量且庞大的数据集,所以看到好的数据集,那还不赶紧收藏一波。
CrossWOZ代码和数据
Abstract
为了推进多域(跨域)对话建模并缓解中文面向任务的数据集的不足的问题,我们提出了CrossWOZ,这是第一个大规模的中文跨域“人机交互”任务导向的数据集。CrossWOZ包含 6K 个对话,102K 个句子,涉及 5 个领域(景点、酒店、餐馆、地铁、出租)。此外,语料库包含丰富的对话状态注释,以及用户和系统端的对话行为。大约60%的对话具有跨域用户目标,这些目标有利于域间依赖性,并有助于对话中跨域自然过渡。我们还为pipeline的面向任务的对话系统提供了一个用户模拟器和一些基准模型,这将有助于研究人员在该语料库上比较和评估他们的模型。CrossWOZ的规模庞大和丰富注释使它适合研究跨域对话建模中的各种任务,例如对话状态跟踪,策略学习,用户模拟等。
Introduction
许多语料库已经推进了面向任务的对话系统的研究,不过大部分都是单领域对话,比如ATIS、DSTC 2、Frames、KVRET、WOZ 2.0和M2M等。这些数据集的大小,语言变化或任务复杂性仍然受到限制。在现实生活中的对话中,人们自然会在不同领域或场景之间进行转换,同时仍保持连贯的上下文,因此,现实对话比仅在单个域中模拟的对话要复杂得多。提及到多领域对话语料,最多被提及的就是MultiWOZ,但是,这个数据集状态注释有很多噪音,并且缺少用户端对话行为。跨域的依赖关系可以简单地体现为对不同的域施加相同的预先规定的约束,例如要求将旅馆和景点都定位在城镇中心。,如下是一个对话示例:
跨领域对话的数据样例
本数据集的特点:
- 用户在某个领域的选择可能会影响到与之相关的领域的选择,在跨领域上下文理解更有挑战。
- 第一个大规模中文跨领域任务导向数据集。
- 在用户端和系统端都有详细的对话状态记录,标注信息全面。
与其他数据集的对比
Related Work
对话数据的收集方式有三类:
- human-to-human
- human-to-machine
- machine-to-machine
Data Collection
语料库是模拟旅行者寻找旅游信息并计划其在北京旅行的场景,domains包括酒店,景点,餐厅,地铁和出租车。 数据收集过程总结如下:
- 基础数据库的构建:通过爬虫从网络上获取了北京市的酒店/旅游景点/饭店以及地铁和出租车信息。
- 目标构建:论文通过算法自动生成标注人员的对话目标。
- 对话收集:要求工人进行少量对话,并向他们提供有关对话质量的反馈。
- 数据标注:每个对话都包含结构化的目标,任务描述,用户状态,系统状态,对话行为和对话。
基础数据库信息示例如下:
用户目标示例如下: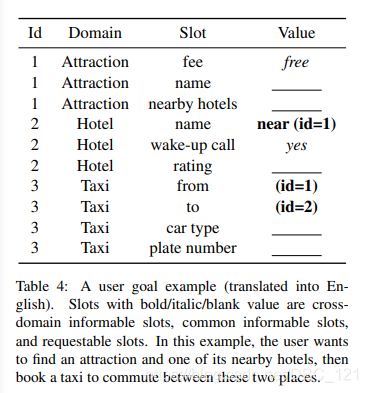
Statistics



Benchmark and Analysis

Conclusion
在本文中,我们提出了第一个大规模的中文跨域任务导向对话数据集,CrossWOZ。CrossWOZ包含 6K 个对话,102K 个句子,涉及 5 个领域。此外,语料库包含丰富的对话状态注释,以及用户和系统端的对话行为。大约60%的对话具有跨域用户目标,这鼓励了相关域之间的自然过渡。得益于丰富的对话状态注释以及用户端和系统端的对话行为,该语料库为研究跨域对话建模的各种任务(例如对话状态跟踪,策略学习等)提供了新的测试平台。我们的实验表明,跨域约束对于所有这些任务都是具有挑战性的。相关领域之间的转换对建模尤其具有挑战性。 除了基于语料库的组件级评估外,我们还使用用户模拟器执行了系统级评估,这需要针对pipeline跨域对话系统的所有组件提供更强大的模型。